『machine learning-7』neural network
神经网络
一、感知器
感知器的定义:以一个实值向量为输入,计算输入中各分量的线性组合,最后通过激活函数计算输出
感知器的输出计算公式: \[ o(x_1, ..., x_n) = \begin{cases} 1 & \omega_0 + \omega_1 x_1 + ... + \omega_n x_n \gt 0 \\ -1 & \text{otherwise} \end{cases} \] 上式中激活函数取符号函数\(sgn(x)\)
注意:一般会设置一个固定的输入\(x_0 = 1\),则上面的不等式可写成 \(\sum_{i=0}^n \omega_i x_i \gt 0\)
感知器的表征能力:可解决线性可分问题
线性可分:设样例是n维实例空间中的点
若存在一个超平面决策面正好可以将正反样例划分开,说明被划分的集合称为线性可分集合
超平面方程即为 \(\vec{\omega} \cdot \vec{x} = 0\)
m-of-n 问题:设1为布尔真、0为布尔假;要使得感知器输出为真,则感知器的n个输入中至少需有m个输入为真
设置所有的 \(\omega_i\) = 0.5(\(i \ge\) 1),再设置适当的阈值(\(\omega_0\))即可;如“或门”的\(\omega_0 \gt -0.5\)
注意:“与或非”都是常见的线性可分运算,“异或”不是(不能用单一的感知器计算)
感知器的训练法则:从随机的一组权值开始,将所有训练样例提交给感知器
只要出现误分类就修改权值,直至感知器正确分类所有样例,设输入样例\((x_i, t)\)对应的权值为\(\omega_i\): \[ \begin{align} \omega_i &\leftarrow \omega_i + \Delta \omega_i \\ 其中权重增量 \ \Delta \omega_i &= \eta (t - o)x_i \end{align} \] 其中o表示感知器的当前输出,\(\eta \in (0, 1)\)表示学习速率
由训练法则可知,若当前输出与样例属性值相等,对应权值就不会调整
梯度下降和delta法则:
感知器训练法则:仅能对线性可分的样本做分类
delta法则:通过梯度下降求出非线性可分计算的最佳近似(学习率 * 输入值 * 输出误差)
梯度下降:搜索使误差最小化的权值向量,设线性单元输出\(o(\vec{x}) = \vec{\omega} \cdot \vec{x}\)
训练误差:\(E(\vec{\omega}) = \frac{1}{2} \sum_{d \in D} (t_d - o_d)^2\)
其中D是样本集,\(t_d\)是样本属性值,\(o_d\)是当前线性单元的输出
梯度:函数E上升最陡峭的方向,\(\nabla E = (\frac{\partial E}{\partial \omega_0}, ...,\frac{\partial E}{\partial \omega_n})\),故设调整方向 \(\Delta \vec{\omega} = -\eta \nabla E(\vec{\omega})\)
梯度下降算法:初始化\(\Delta \omega_i = 0\),对训练样本中的所有样本\((\vec{x}, t)\),累计计算所有的权值增量: \[ \Delta \omega_i \leftarrow \Delta \omega_i + \eta (t - o) x_i \] 最后调整各权值分量: \[ \omega_i \leftarrow \omega_i + \Delta \omega_i \] 注意:学习速率\(\eta\)必须足够小,以防止步幅过大跨过最小误差对应的权值向量
随机梯度下降:解决收敛速度过慢或陷入局部极小的问题
- 标准梯度下降:在权值更新之前先汇总所有样例的误差 \[ \Delta \omega_i = \eta \sum_{d \in D} (t_d - o_d)x_{di} \] 随机梯度下降:根据每个样例\((\vec{x}, t)\)直接更新各权值 \[ \Delta \omega_i = \eta (t - o) x_i \]
注意:感知器训练法则是根据阈值输出调整权值,而delta法则是直接根据线性单元输出调整权值
二、多层网络和反向传播算法 ⭐
多层网络:具有隐藏层,能够表示高度非线性的决策面(如曲面)
可微阈值单元:适用于梯度下降算法非线性的可微函数
sigmoid函数:常见的平滑可微的阈值函数 \[ \text{sigmoid}(x) = \frac{1}{1 + e^{-x}} \]
sigmoid函数的特殊性质:记sigmoid为\(\sigma\),有\(\sigma' = \sigma(1-\sigma)\)
反向传播算法(BP算法):通过梯度下降最小化网络输出值和目标值之间的误差平方
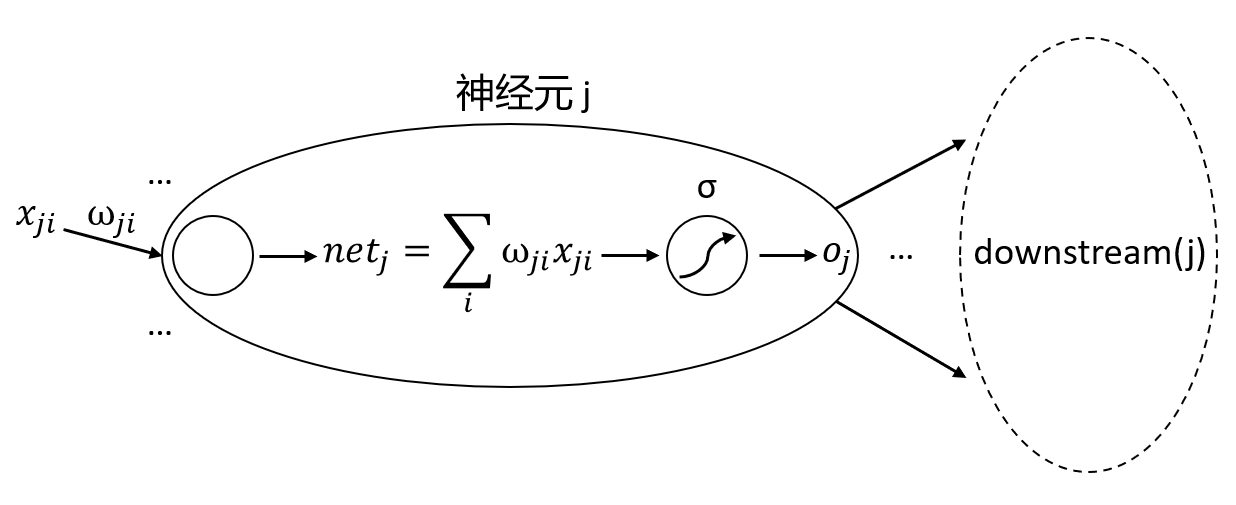
设\(x_{ji}\)为神经元j的第i个输入,\(\omega_{ji}\)表示对应的权重,\(net_j\)表示神经元j输入的线性加权,\(o_j\)表示神经元j的阈值输出
downstream(j) 表示以神经元j的输出为直接输入的下一层神经元的集合
 对于训练样本集中的每个样例\((\vec{x_i},
t)\),将其输入网络,使误差沿网络反向传播:
对于训练样本集中的每个样例\((\vec{x_i},
t)\),将其输入网络,使误差沿网络反向传播:对于网络中的每个输出神经元k,计算其误差项 \(\delta_k = o_k(1-o_k)(t_k - o_k)\) (\(\sigma' \Delta out)\)
对于网络中的每个隐层神经元h,计算其误差项 \(\delta_h = o_h(1-o_h) \sum_{k \in downstream(h)} \delta_k \omega_{kh}\)(\(\sigma' \sum \Delta\),向前递推)
第m层神经元的误差项是由所有第m+1层神经元的误差项推导出来的
更新各网络权值\(\omega_{ji} \leftarrow \omega_{ji} + \Delta \omega_{ji}\),其中 \(\Delta \omega_{ji} = \eta \delta_{j} x_{ji}\)
反向传播算法的终止条件:固定的迭代次数(一轮迭代指读取一遍训练集),或误差降至某个阈值以下
注意:上面的BP算法适用于任何“无环”网络学习,downstream也不要求各层网络中的神经元整齐排列在一行内
BP算法的推导思路:设样本d的误差平方\(E_d(\vec{\omega}) = \frac{1}{2} \sum_{k \in outputs} (t_k - o_k)^2\)
由梯度下降算法,对每个训练样例d,需要求解 \(\Delta \omega_{ji} = -\eta \frac{\partial E_d}{\partial \omega_{ji}}\),即调整梯度的增量
神经元j的输入权值\(\omega_{ji}\)仅通过加权和\(net_j\)影响后方的网络,由链式法则: \[ \begin{align} \frac{\partial E_d}{\partial \omega_{ji}} &= \frac{\partial E_d}{\partial net_j} \frac{\partial net_j}{\partial \omega_{ji}} \\ &= \frac{\partial E_d}{\partial net_j} x_{ji} = -\delta_j x_{ji} \end{align} \] 若神经元j是输出神经元:神经元j的加权和\(net_j\)仅通过输出\(o_j\)影响后方的网络 \[ \begin{align} \frac{\partial E_d}{\partial net_j} &= \frac{\partial E_d}{\partial o_j} \frac{\partial o_j}{\partial net_j} \\ &= \frac{\partial}{\partial o_j}[\frac{1}{2} (t_j - o_j)^2] \frac{\partial \sigma(net_j)}{\partial net_j} \\ &= -(t_j - o_j)o_j(1-o_j) \end{align} \] 若神经元j是隐层神经元:神经元j的加权和\(net_j\)通过其所有下游神经元影响后方的网络 \[ \begin{align} \frac{\partial E_d}{\partial net_j} &= \sum_{k \in downstream(j)} \frac{\partial E_d}{\partial net_k} \frac{\partial net_k}{\partial net_j} \\ &= \sum_{k \in downstream(j)} -\delta_k (\frac{\partial net_k}{\partial o_j} \frac{\partial o_j}{\partial net_j}) \\ &= \sum_{k \in downstream(j)} -\delta_k \omega_{kj} o_j(1-o_j) \\ &= -o_j(1-o_j) \sum_{k \in downstream(j)} \delta_k \omega_{kj} \\ &= -\delta_j \end{align} \]
收敛性与局部极小值
基于迭代的反向传播算法可能导致误差E收敛到某个局部极小值
如何缓解局部极小值问题:“启发式规则”
为梯度增量增设一个冲量项:\(\Delta \omega_{ji}(n) = \eta \delta_jx_{ji} + \alpha \Delta \omega_{ji}(n - 1)\)
其中增加的第二项就是冲量项,冲量常数 \(0 \le \alpha \lt 1\);n表示第n轮迭代
冲量项有可能助力网络跳出局部极小值
以多组不同初始权重训练神经网络,取其中误差E最小的参数训练结果作为最终参数(相当于从多个初始点开始搜索)
使用“模拟退火”技术:模拟退火的每一步迭代都以一定概率接受比当前解更差的结果,从而有概率跳出局部极小值
三、关于神经网络的拓展讨论
误差函数的选取:除了误差平方和函数E,还有其它目标函数可供选择
为权值增加一个惩罚项:通过权重的平方和考察网络的复杂程度,减小过拟合的风险,\(\gamma \in (0, 1)\) \[ E(\vec{\omega}) = \frac{1}{2} \sum_{d \in D} \sum_{k \in outputs} (t_{kd} - o_{kd})^2 + \gamma \sum_{i, j} \omega_{ji}^2 \]
对误差增加一项目标函数的斜率或导数:考察训练导数和网络的实际导数间的差异 \[ E(\vec{\omega}) = \frac{1}{2} \sum_{d \in D} \sum_{k \in outputs} [(t_{kd} - o_{kd})^2 + \mu \sum_{j \in inputs}(\frac{\partial t_{kd}}{\partial x_d^j} - \frac{\partial o_{kd}}{\partial x_d^j})^2] \] 其中\(x_d^j\)表示训练实例d的第j个输入单元的值
设置目标值为交叉熵:将离散的分类输出转化为连续的概率输出,交叉熵定义: \[ -\sum_{d \in D} t_d\log o_d + (1 - t_d)\log(1 - o_d) \] 其中 \(o_d\) 表示对样例d输出的概率估计,\(t_d\) 表示训练样例的目标值
深度学习:一般指很深层的神经网络
无监督逐层训练:“预训练 + 微调”:
- 预训练:每次训练一层隐节点:
- 将上一层隐节点的输出作为输入
- 将本层隐节点的输出作为下一层隐节点的输入
- 微调:预训练全部完成后,对整个网络进行微调
这种训练方式实际上是从各层局部最优出发寻找全局最优
- 预训练:每次训练一层隐节点:
“权共享”策略:让一组神经元共享相同的连接权,在卷积神经网络中应用较多
卷积层:包含多个特征映射,即神经元组成的平面
特征映射:其中的每个神经元负责从输入的部分区域内通过卷积滤波器提取特征
采样层:其中的每个神经元负责从特征映射层的部分区域计算输出,起到精简数据量的作用
通过复合卷积层 + 采样层,最终实现了将高维信息映射到低维数据的效果
注意:层数越多,特征越全局
池化:对不同位置的特征值进行聚合统计(max or min or random),达到降维 + 防止过拟合的效果
梯度消失:随着隐藏层数量的增加,不同层之间的梯度开始消失,下面是常见的解决方案:
- 线性整流激活函数:ReLU(x) = max(0, x)
- 归一化:对激活后的输出进行归一化
- 残差网络:在输入和输出之间添加跳跃连结,允许梯度直接流过