『paper-MM-2』《Evaluating Adversarial Robustness of Large VLMs》
《On Evaluating Adversarial Robustness of Large Vision-Language Models》
From Advances in Neural Information Processing Systems (2023)
一、本文贡献
- 评估当前 SOTA VLMs 的视觉对抗鲁棒性,对开源 VLMs 进行黑盒攻击
- 基于替身模型的迁移攻击可以对 VLMs 进行定向诱导
- 定量揭示了当前基于 VLM 的应用(robots/agents)的对抗性脆弱,尤其在视觉模态异常脆弱
二、相关工作
大语言模型及其鲁棒性:
多模态大模型及其鲁棒性:
- 经典工作:PaLM-E、KOSMOS-1、Visual-ChatGPT 等
- 针对 MLLMs 的 VQA 任务或 Image Caption 任务的鲁棒性探究
相较于过去针对 CNN-RNN-based 的白盒非定向攻击、本篇工作聚焦于针对 VLM 的黑盒定向攻击
三、研究方法
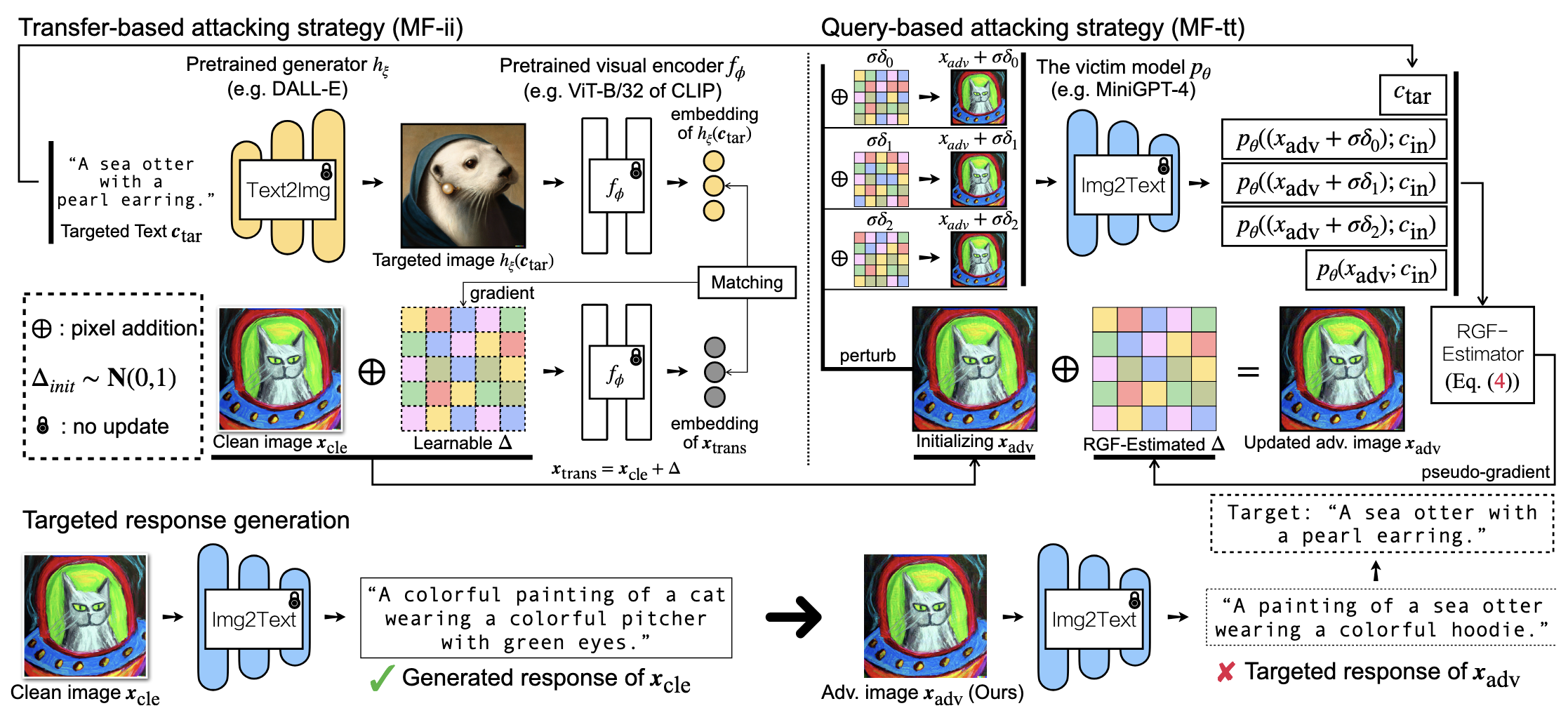
威胁模型:基于图像的生文任务可建模为 \(p_{\theta}(x;c_{\text{in}}) \vdash c_{\text{out}}\),其中 \(x\) 是输入图像、\(c_{\text{in}}\) 是输入文本,\(c_{\text{out}}\) 是输出文本
- 对抗性知识:攻击者对受害模型的了解程度,对应地可以分为黑盒攻击和白盒攻击
- 对抗性目标:可以分为非定向攻击(\(c_{\text{out}}\) 只需保证是错误的)和定向攻击(\(c_{\text{out}}\) 必须符合预先指定的 \(c_{\text{tar}}\))
- 对抗性能力:限定了攻击者可干扰的范围边界 \(\epsilon\);对于 \(p\) 范数干扰需满足约束 \(||x_{\text{cle}} - x_{\text{adv}}||_p \le \epsilon\)
本文提出了一种"两阶段"的攻击策略:Transfer-based attacking (MF-ii) 和 Query-based attacking (MF-tt)
Transfer-based attacking:针对替代模型设计攻击策略,再迁移到黑盒受害模型上;总体跨模态攻击目标如下 \[ x_{\text{adv}}^{*} = \underset{||x_{\text{cle}} - x_{\text{adv}}||_p \le \epsilon}{\text{argmax}} f_{\phi}(x_{\text{adv}})^{\text{T}} g_{\psi}(c_{\text{tar}}) \] 其中 \(f_{\phi}\) 是 image encoder,\(g_{\psi}\) 是 text encoder,均为开源的替代模型;带 \(\epsilon\) 限制的优化问题可用 PGD 算法求解
本文用预训练T2I模型 \(h\) 先生成对抗性图片,再在同一个图像空间内对齐;第一阶段的攻击目标如下 \[ x_{\text{adv}}^{*} = \underset{||x_{\text{cle}} - x_{\text{adv}}||_p \le \epsilon}{\text{argmax}} f_{\phi}(x_{\text{adv}})^\text{T} f_{\phi}(h(c_{\text{tar}})) \]
Query-based attacking:在生成文本的语义空间内对齐,同样可使用 PGD 算法求解;第二阶段的攻击目标如下 \[ x_{\text{adv}}^{*} = \underset{||x_{\text{cle}} - x_{\text{adv}}||_p \le \epsilon}{\text{argmax}} g_{\psi}(p_{\theta}(x_{\text{adv}}; c_{\text{in}}))^{\text{T}} g_{\psi}(c_{\text{tar}}) \] 其中 \(x_{\text{adv}}\) 来自第一阶段的输出结果,也即第二阶段的输入参数是第一阶段的输出结果
由于无法获得 \(p_{\theta}\) 的参数 \(\theta\),本文采用 Random Gradient-Free 算法估计 \(\theta\) ;设 \(p_{\theta}\) 是可微分的,可通过估计多个方向导数估算梯度 \[ \begin{align} &\nabla_{x_{\text{adv}}} g_{\psi}(p_{\theta}(x_{\text{adv}};c_{\text{in}}))^\text{T} g_{\psi}(c_{\text{tar}}) \\ \approx & \dfrac{1}{N} \sum_{n=1}^N [\dfrac{g_{\psi}(p_{\theta}(x_{\text{adv}}+\sigma \delta_n;c_{\text{in}}))^\text{T} g_{\psi}(c_{\text{tar}}) - g_{\psi}(p_{\theta}(x_{\text{adv}};c_{\text{in}}))^\text{T} g_{\psi}(c_{\text{tar}})}{\sigma}] \cdot \delta_n \end{align} \] 其中 \(\delta_n \sim P(\delta)\) 可以从超球面随机取点以模拟不同的方向,\(N\) 表示 query T2I 的总次数
注意:先前的工作会把 Transfer-based 和 Query-based 两阶段并行执行,本文方法将两个阶段串行执行,对抗攻击效果更优
四、实验评估
Ours 优于 直接基于跨模态优化的方案,两阶段扰动范围 \(\epsilon_{t}, \ \epsilon_i\) 均不能为 0
Ours 优于 单一Transfer-based/Query-based的方案
Ours 生成的混淆噪声 \(\Delta = x_{\text{cle}} - x_{\text{adv}}\) 并不携带有效的语义信息/显著的视觉信号
Ours 需要选取适当的 \(\epsilon \in [0, 255]\),以达到 图像质量 \(\Leftrightarrow\) 目标诱导性 之间的平衡(LPIPS)
原始text-input下,GradCAM 在 \(x_{\text{adv}}\) 上更多地关注无用的背景,说明 VLM 的关注点遭受到不良影响
对抗text-input下,GradCAM 在 \(x_{\text{cle}}\) 和 \(x_{\text{adv}}\) 上关注了相近的部位,说明 VLM 的注意力被对抗样本带偏了