『paper-MM-1』《A Survey on Threats in LLM-Based Agents》
《A Survey of Security, Privacy, and Ethics Threats in LLM-Based Agents》
From arXiv (2024)
一、LLM-Based Agents 安全
与启发式/强化学习 Agents 的区别:LLM Agents 可与用户交流,其庞大的知识量可支撑其像人类一样理解 + 规划
LLM-Based Agents 的脆弱性:多轮对话 + 多源输入 为智能体引入了更多威胁
现有的针对安全威胁的分类学:模块化 or 阶段化
- 模块化:输入模块 + 决策模块 + 工具链模块 + 输出模块
- 阶段化:感知阶段 \(\rightarrow\) 内部执行阶段 \(\rightarrow\) 环境执行阶段 \(\rightarrow\) 外部交互阶段
各种威胁往往是跨模块/跨阶段的,难以精确定位到单个模块/阶段
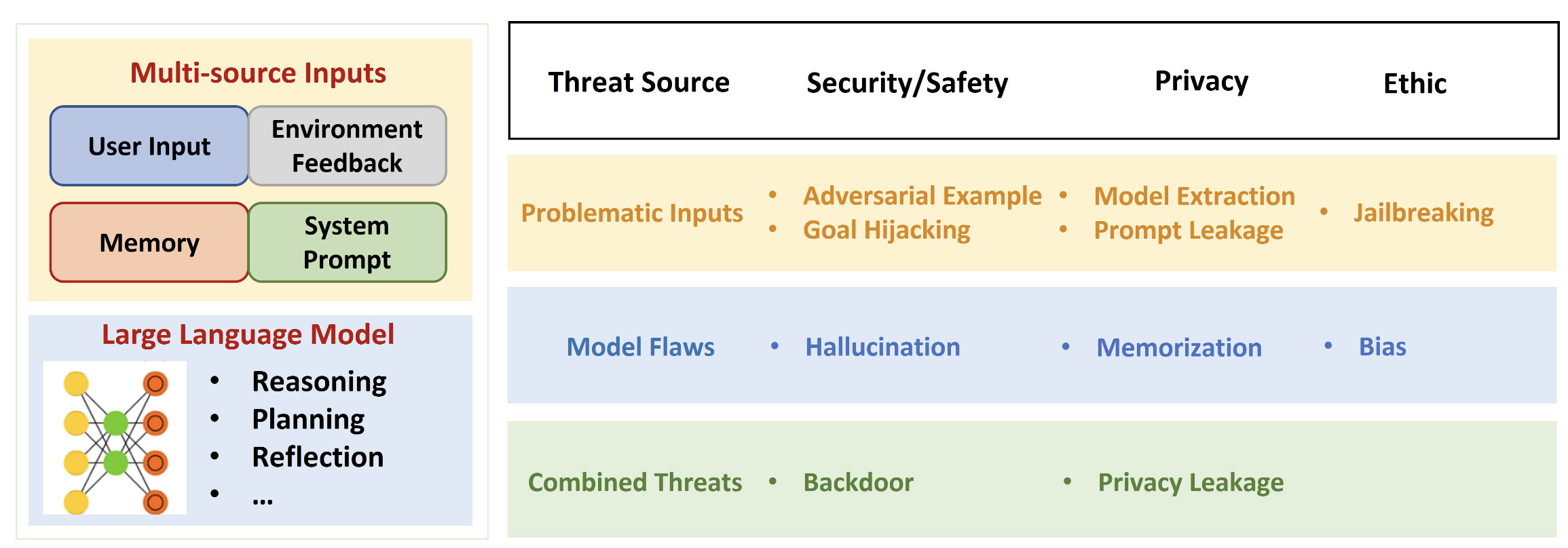
全新的分类学:基于 威胁源+威胁类型 的分类方法
- 威胁源:模型输入 or 模型本身 or 两者混合(左 1/4)
- 威胁类型:安全 or 隐私 or 道德(右 3/4)
二、关于 LLM-Based Agents
LLM-Based Agents 结构:
- 输入模块:接收用户输入 \(\rightarrow\) 检测有害信息 or 纯化 \(\rightarrow\) 追加提示词
- 决策模块:根据用户输入给出规划和回应;简单任务可使用单一 LLM,复杂任务可使用多 LLM 实现
- 外挂实体:将 记忆模块 (数据库 or RAG) + 外部工具 (搜索引擎 or 机械单元) 作为执行复杂任务的辅助工具
- 输出模块:任务执行结束后,agents 通过输出模块向用户返回结果,同时执行安全检测
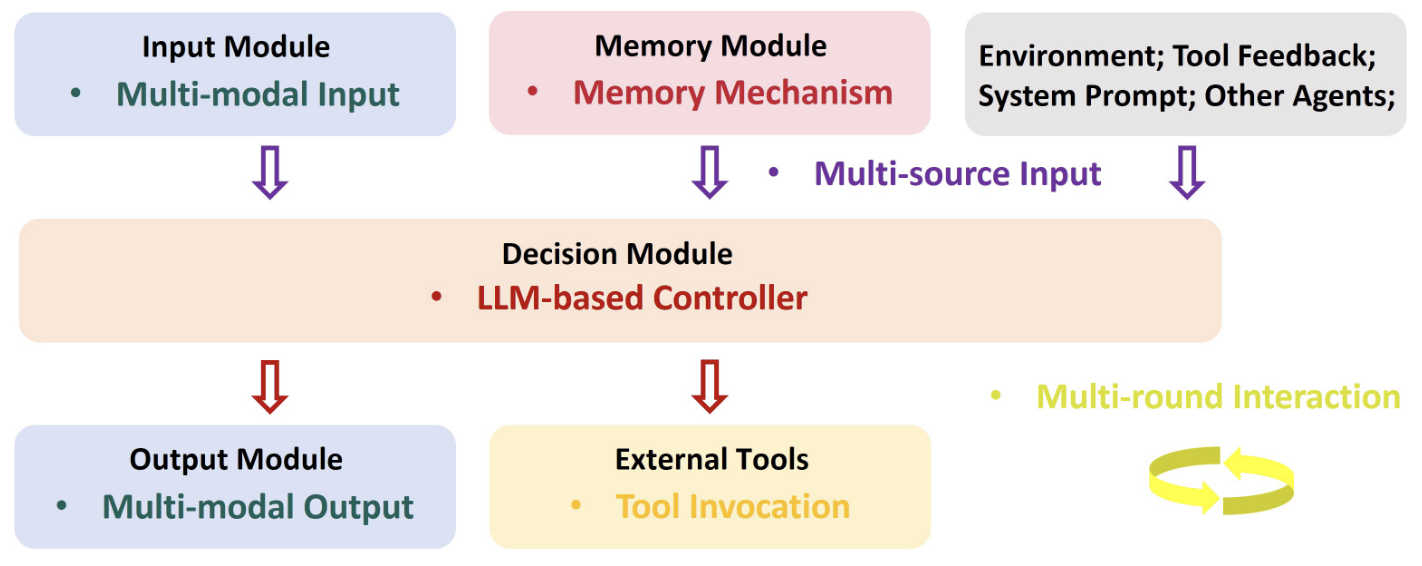
LLM-Based Agents 特征:如下特征带来了新的安全隐患
- LLM 核心控制器:agents 的控制核心,具备强大的理解规划能力
- 多模态输入输出:复杂任务场景需要引入多模态输入输出
- 多源输入:LLM core 与 用户、系统提示词、外挂 和 外部环境 交互
- 多轮交互:LLM core 在复杂任务中需要与 上述对象 进行多轮交互
- 记忆机制:记忆模块帮助 agents 积累经验知识、提高解决多样化问题的能力
- 工具调用:LLM 经过指令微调可以调用工具,从而执行更加复杂的任务
三、输入风险
对抗样本:经过微小扰动的、保留原始语义,但是能够混淆目标模型的样本,形式如下: \[ \begin{align} \delta^{*} &= \text{argmin}_{\delta \in \Delta} SemDist(x, \ x+\delta) \\ & \text{s.t.} \begin{cases} g(x+\delta^{*}) \ne o & (\text{untargeted}) \\ \\ g(x+\delta^{*}) = t & (\text{targeted}) \end{cases} \end{align} \] 其中 \(\Delta\) 表示可行的扰动范围,\(g\) 表示深度学习模型,\(SemDist\) 表示语义间距,\(o\) 是原始的样本输出标签
目标劫持:通过某种对抗性输入,使模型偏离原始意图
模型窃取:用尽可能低的开销获得接近于黑盒商用模型的克隆模型
提示词泄露:攻击者通过某种手段获得系统提示词(用来执行任务规划的内部提示词)
『paper-MM-1』《A Survey on Threats in LLM-Based Agents》
http://larry0454.github.io/2024/11/22/paper/MM/agent/navigate-the-risks/