『paper-NLP-2』《RAG for NLP: A Survey》
《RAG for NLP: A Survey》
From arXiv (2024)
一、LLM 的问题
- “幻觉“问题:LLM 会生成看似合理流畅,但实际是错误的回答
- ”知识更新“问题:基于新的知识重新训练/微调 LLM 开销非常大
- “特定领域”问题:LLM 不具备针对特定领域的专业知识
二、Retriever
Retriever 的组成:三部分
- encoder:将 inputs 编码为 embeddings
- indexing:基于ANN(近似最邻近算法)查询相关向量
- datastore:以“K-V”形式存储外部知识的数据库
构造 Retriever:四步骤
语料切块:将原始文档切分为小块
- 分块间语义应相互独立,各分块语义不应模糊,只能包含一种核心观点
- 对较短的分块编码速度更快,更省显存
分块大小是决定分块语义+编码效率的核心因素,分块大小取决于RAG场景:
- 任务角度:问答任务用小块,摘要任务用大块
- 编码角度:编码器模型决定了适用的分块大小
- 查询角度:分块大小应与用户查询大小匹配
分块方法:三种
- 定长分割
- 基于语义分割:按 语句周期 or 换行 分割
- 基于内容分割:按 章节 or 代码块 分割
切块编码:
- 稀疏编码:用高维向量表示一段 chunk,向量中有很多 0
- 词袋模型:一段 chunk \(\Leftrightarrow\) 一个定长向量,每个维度指对应词出现的次数;只考虑单词数量,不考虑单词位置和语义
- \(\text{TF} \times \text{IDF}\)
:\(\text{TF}(t,d) = \dfrac{t_d}{d}\)
(衡量单词 t 在文档 d 中的重要程度)
\(\text{IDF(t)}=\log (\dfrac{N}{n_t + 1})\) (削弱常见停用词的重要性)
- 稠密编码:基于深度学习模型生成,每个维度是浮点数,记录语义信息,0 很少
- 稀疏编码:用高维向量表示一段 chunk,向量中有很多 0
构建索引:加速高维空间中与用户 query 接近的向量
- 相似度衡量:余弦相似度,欧氏距离,曼哈顿距离 等
- 嵌入降维:PCA、LSH,以及 Product Quantization (子空间码本)
降低 embed 维度可提高搜索效率,但也可能丢失语义信息 - ANN索引:优化存储结构,从而优化ANN算法
构建向量数据库:K\(\leftrightarrow\)V 指 domain-specific embed \(\leftrightarrow\) domain-specific chunk
算法见 (Algorithm Wu 等, 2024, page 4),以分块嵌入 \(e_i\) 为 key,以分块 \(c_i, c_{i+1}\) 为 value,并在 key 上建索引

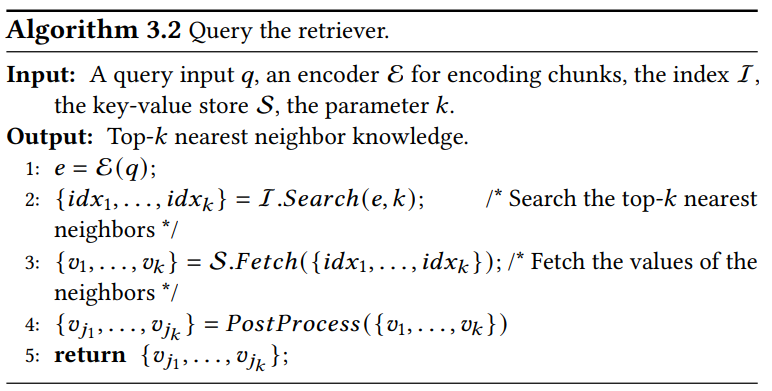
查询 Retriever:两步骤
- 查询编码:查找相关性 top-k 的索引,返回数据库中对应的 values
- 后处理:重排序 (根据任务类型重新排序)
Retriever 融合:三种
query-based:先编码 query 和各 retrievals (可选),再拼接 query 和 retrievals,最后输入给 LLM
算法见 (algorithm Wu 等, 2024, page 6)
logits-based:先将 query 和各 retrievals 输入 LLM,再对各输出响应加权求和
算法见 (algorithm Wu 等, 2024, page 6),有“集成”和“校准”两种方法
latent-based:将 retrievals 融入 LLM 的 hidden-states
算法见 (algorithm Wu 等, 2024, page 7),有"attention-based"和"weighted"(开销较小)两种集成方法,RAG 使用较多
三、Generator
- LLM 经典分支:Llama, GPT, Gemini 等
- 当前 RAG 多设计拓展模块,采用 latent-based 方法
四、RAG Training
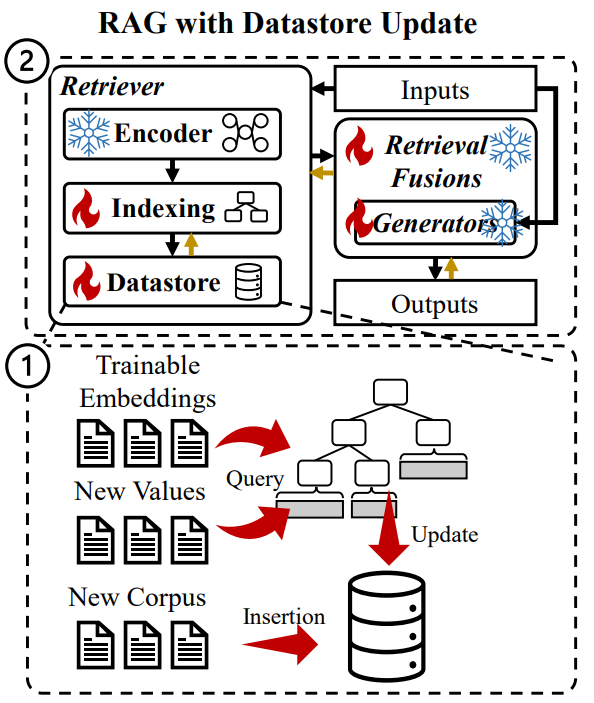
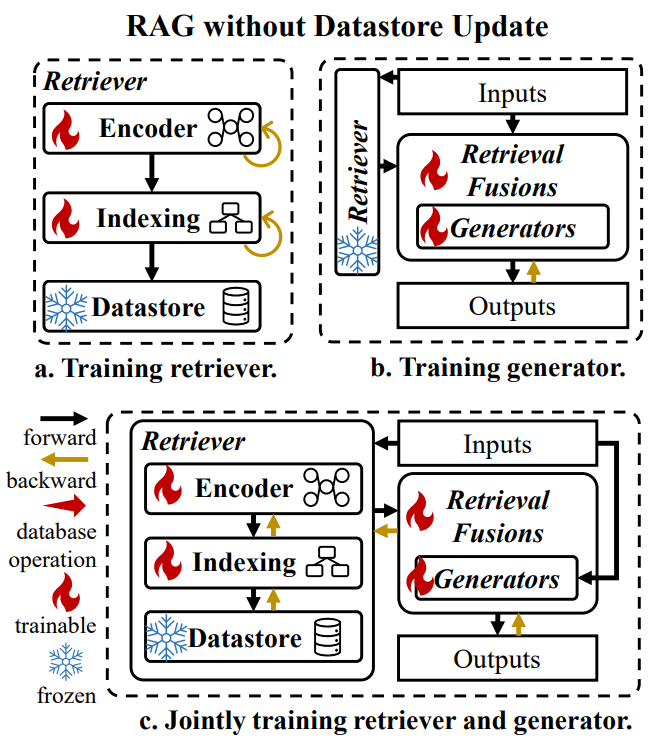
训练方案:两种,”数据库更新”和“数据库不更新”
数据库不更新:三种方式
训练 Retriever:仅针对 dense-encoder,用于提升语义表征、加速编码,或 学习特定领域的知识
encoder 改变 \(\rightarrow\) embed 改变 \(\rightarrow\) index 改变训练 Generator:LoRA
联合训练:端到端优化,同时提升 retriever 和 generator
数据库更新:插入新的 K-V 或 修改 values