『database-6』memory management
存储管理与索引
一、物理存储系统
存储分级:数据库中的数据只有调入内存中才能被处理,DBMS管理内存与外存的数据交换
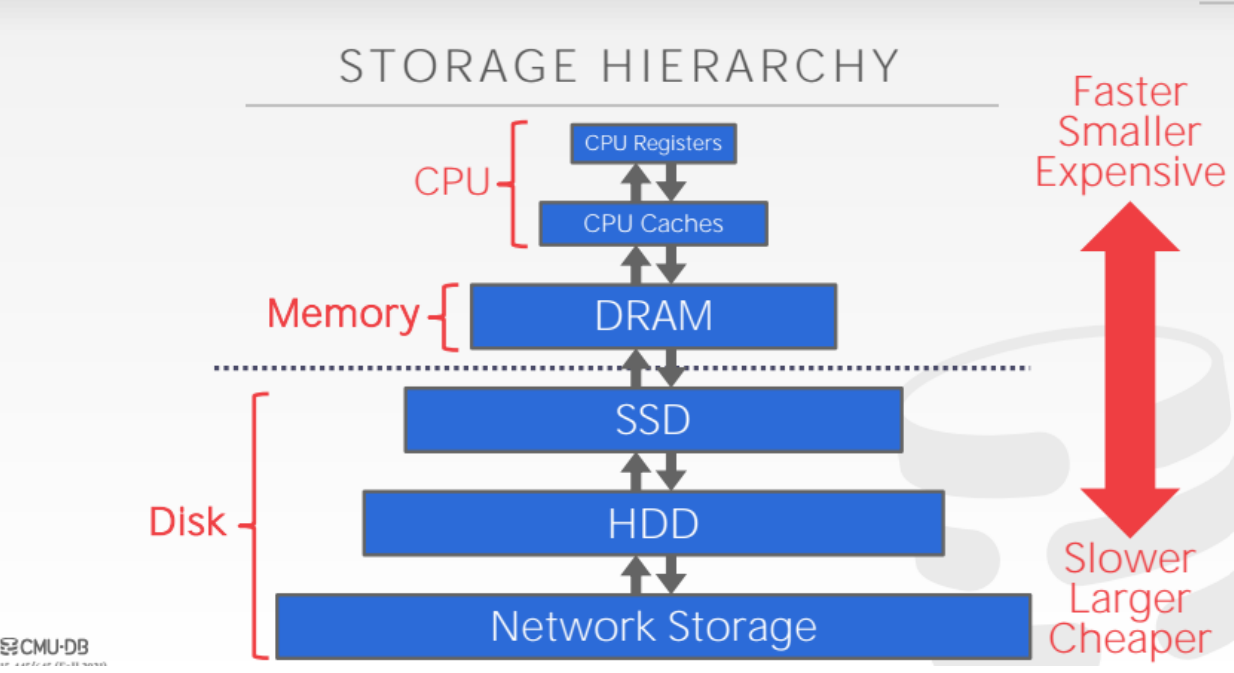
DBMS存储管理目标:最小化访问磁盘的次数
磁盘块(内存中指页):由若干连续的扇区组成,是存储分配与检索的逻辑单元
磁盘访问时间:寻道时间 + 旋转时间 + 传输时间
物理存储管理器:DBMS结构中最底层模块,隔离上层与底层的模块
- 交换单元:以磁盘块(物理页)为基本单位
- 基本功能:负责数据在磁盘与主存之间的移动
- 实现方法:调用操作系统文件接口 or DBMS自己实现(支持跨平台 + 功能扩展)
二、数据库存储结构:
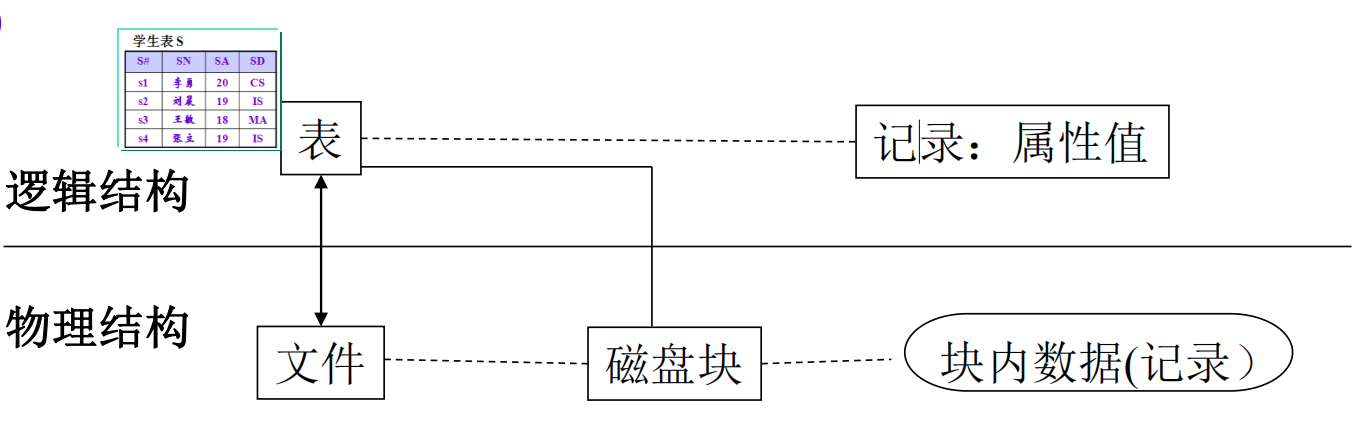
数据库:由若干文件组成;一个表被映射到一个文件
文件:存放在若干磁盘块上;块是存储分配与数据传输的基本单位 注意:文件可以占据连续的磁盘块 or 链接的磁盘块 or 簇(内部连续)分配磁盘块 or 索引分配磁盘块(含索引块)
记录:文件数据的基本单位;一条记录只属于唯一的块
数据库页/块:存储元组(记录)、元数据、索引,一般使用分槽页结构:
- Header:已使用的槽数 + 最后一个被使用槽的起始位置偏移 + 槽数组
- slot:存储对应tuple在该页中的起始位置的偏移量
- 增加记录:槽数组从开始到尾部增长、记录数据从数据区尾部向开始方向生长
记录:由DBMS负责解释为属性类型与对应值
- 记录头部:元数据、如加锁信息
- 记录数据:属性对应的实际数据,按表定义的属性顺序存储
- 唯一标识符ID:每个纪录被分配一个ID,如 页ID-slot
注意:文件中的记录存放可以是 堆 + 顺序 + 索引 + 散列 + 聚集
- 堆文件组织:链表方式(header页)+ 页目录方式(借助特殊页保存文件在数据页中的位置)
- 顺序文件组织:记录按搜索码顺序在文件中排列;通过指针把记录链接起来
- 索引文件组织:包括了主文件(存放记录) + 索引表(key \(\rightarrow\) addr)
- 索引表:表内索引必须按主关键字key有序排列
- 主文件:主文件中的记录可按主关键字有序组织 or 无序组织
- 散列文件组织:一个文件有N个桶,将键值为k的记录存储在 hash(k)
对应的桶中,
处理溢出使用主桶 链接 多个溢出桶 - 聚集文件组织:将具有相同属性值的记录存储在连续的磁盘块中
一个文件可容纳来自多个关系的记录,适用于连表查询(一次性拿出聚集项),但单表访问会变慢
三、缓冲区管理
缓冲区:内存中的页面数组(元素称为“帧”,存放一个磁盘块副本),页表项包含以下元数据
- Dirty Flag:线程对页修改后设置,通知存储管理器该页必须写回磁盘
- Pin计数器:缓冲页被读写操作时要被Pin住,防止该页被移出
加锁与替换:
- 加锁:读操作加共享锁、更新操作加排他锁
- 替换:LRU (Least Recently Used)
缓冲区管理器:负责缓存空间分配,以及内外存间的交换
执行引擎操作磁盘块:
- 该块在缓冲区中,直接返回该块在内存中的地址
- 该块不在缓冲区,将该块调入缓冲区,并将其内存地址返回给调用者
缓冲区管理目标:最小化磁盘与主存间的传输存储块的数量,可通过在主存中保持尽可能多的块实现
四、索引
索引记录(索引项):索引文件由索引记录组成,包括 索引域 + 指针
- 索引域:存储数据文件中的一个 or 一组域(属性)
- 指针:指向索引域值为K的记录所在磁盘块的地址
排序索引:索引项是排序的
哈希索引:索引项使用索引域上的 hash 函数确定位置
聚集索引与非聚集索引:
- 聚集索引:索引域的排列顺序与对应记录在文件中的排列顺序一致
- 非聚集索引:索引域的排列顺序与对应记录在文件中的排列顺序不一致
稠密索引与非稠密索引:
- 稠密索引:文件中的每个搜索码值都有对应的一个索引项
- 非稠密索引:仅文件中的部分搜索码值有索引记录,仅当文件记录按索引域排序时可以使用
注意:由于非聚集索引不必按索引域值排序,故非聚集索引都是稠密索引
多级索引:外层索引作为基本索引的稀疏索引;内层索引作为基本索引文件,指向数据块
多级索引一般分为“二叉树索引”和“多叉树索引”,可能会导致“非平衡问题”B树:一种自平衡树。根节点有[2, n]个子节点,中间节点有[\(\dfrac{n}{2}\), n]个子节点,叶节点有[(n-1)/2, n-1]个记录指针 注意:B树的关键字散布在各层;所有叶节点都在同一层上
B+树:B树的一种改进,将所有关键字按从左到右递增的顺序安排在叶节点上,并用\(\text{P}_n\)指针链接起来
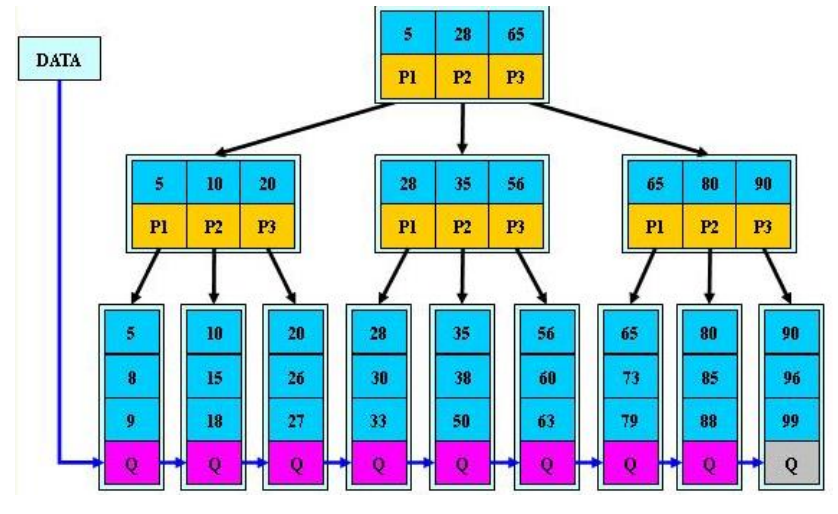
- 查询:从树的根节点开始,比较搜索码V和节点关键字K向下遍历B+树,返回叶节点的记录指针
- 插入:考虑两种情况
- 若叶节点未满直接插入即可(\(\le\) m-1)
- 否则将插入后的叶节点拆成左右两半,并在两个新叶节点间插入父节点索引
Hash 索引:基于哈希表实现
哈希表(散列表):记录 Key \(\rightarrow\) Value 的映射,实现了 Hash 函数
哈希方案:解决一个哈希对应多个冲突的方法,一般采用溢出链接法(桶链表)
静态哈希:哈希表的大小固定,但太多的溢出桶会导致访问性能降低
动态哈希:哈希表的大小可动态修改(重哈希),定期重哈希or线性哈希
注意:Hash索引适用于哈希码取特殊值的记录检索,不适用于区间or部分匹配;有多个重复值的列不适合做key