『database-5』database design
数据库设计
一、数据库设计阶段概览
需求分析:对应用环境进行详细调查,收集支持系统目标的基础数据及其处理
数据库概念结构设计:
- 对用户需求进行综合、归纳与抽象
- 设计独立于数据库逻辑结构与DBMS的概念模型(可用 E-R 图表示)
数据库逻辑结构设计:
- 将概念结构转换为某个DBMS所支持的数据模型,并作优化
- 将得到的逻辑结构转换成特定的DBMS能处理的模式、子模式
数据库物理结构设计:设计物理设备的存储结构与存取方法
- 确定数据库的内模式
- 对物理结构进行时间与空间效率的评价
数据库实施:用DDL描述三级模式,并调试产生目标模式,组织数据入库并试运行
数据库运行与维护:数据库正式运行后,由DBA对数据库维护
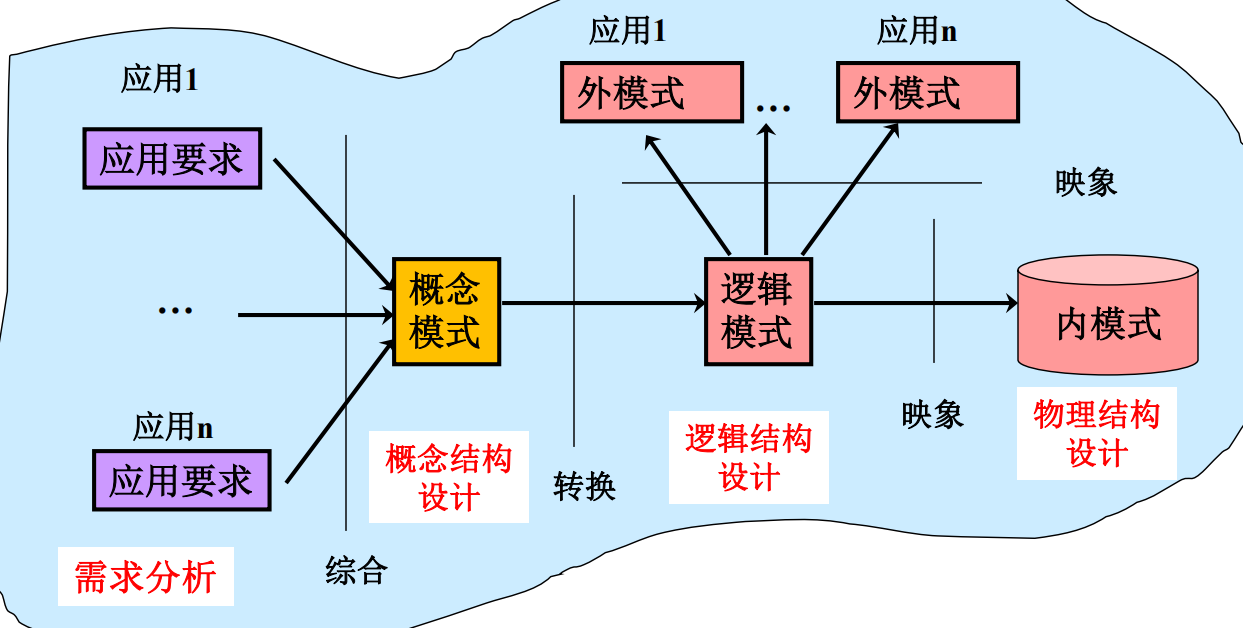
数据库设计阶段
二、需求分析
需求分析的目标:调查重点是“数据”与“处理”
- 处理要求:用户需要完成何种处理功能
- 信息要求:指系统中所涉及的数据及数据间联系
- 安全性与完整性约束
需求分析的步骤:
- 调查用户实际需求,与用户达成共识
- 使用数据流图表达数据处理间的关系;使用数据字典描述系统中的各类数据
数据流图:以图形方式表达系统功能、数据在系统内部的逻辑流向
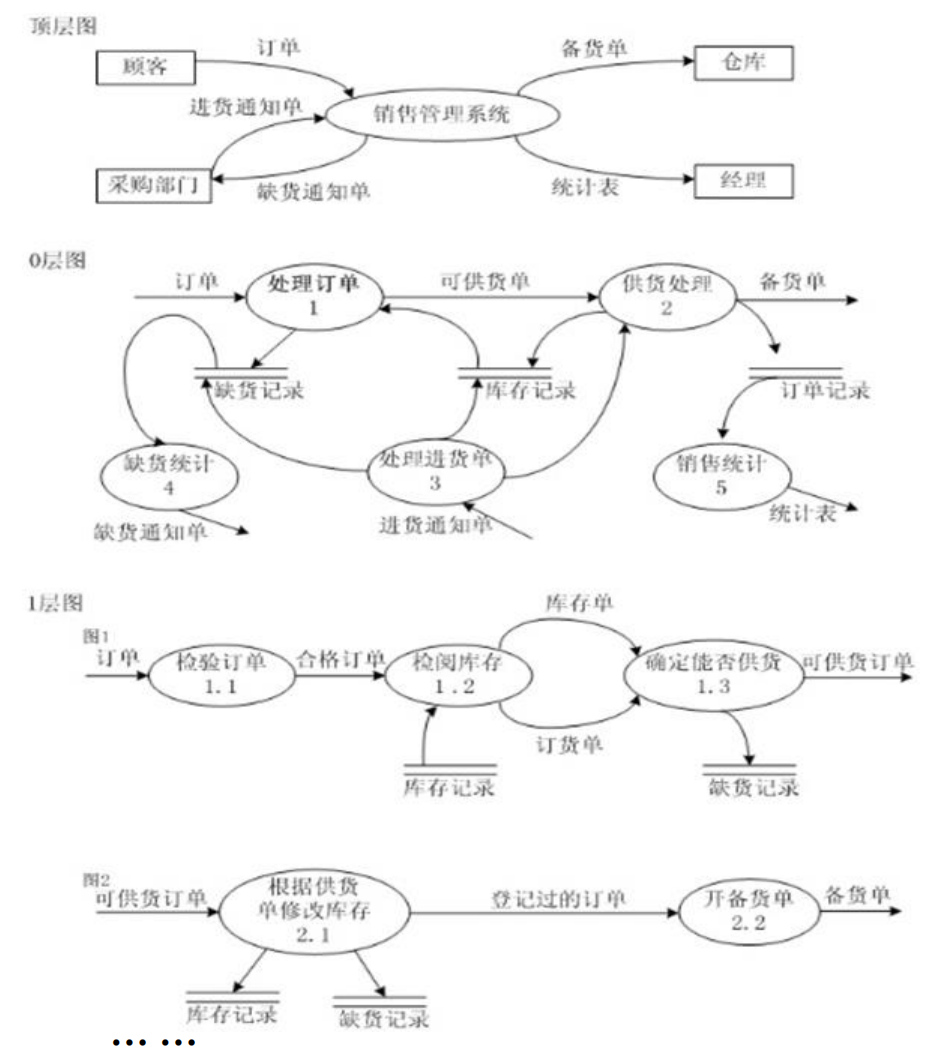
自顶向下分解的 销售管理系统 数据流图 数据字典:对数据库中数据的描述(即元数据),其原子单位是数据项,包含以下
- 数据项语义定义:名字 + 实际含义
- 数据项类型定义:数据类型 + 数据宽度 + 小数位数
- 完整性约束定义:值约束 + 空值约束 + 其它完整性约束
注意:数据字典还包括数据在系统内的传输路径、存储位置等
三、概念结构设计
E-R 法:使用 E-R图 描述现实世界
E-R 图:由实体、联系、属性构成
自底向上的 E-R 图设计方法:先设计局部应用的概念结构,再将其集成起来
局部 E-R 图设计:
- 选择局部应用:将需求分解形成不同的概念模式
- 以需求分析中的数据元素为基础,利用数据抽象机制,得到实体与属性
注意:“数据抽象”包括分类(对象的类型)、聚集(类型的组成)和概括(类型间的联系) - 确定实体间的联系类型,用 E-R 图表示这些实体与实体间的联系,形成分 E -R 图
综合局部 E-R 图:将分 E-R 图合并,消除冲突与冗余,最终形成基本 E-R 图
生成初步 E-R 图:消除分 E-R 图的冲突,需消除属性冲突 + 命名冲突 + 结构冲突
- 属性冲突:属性的类型、取值范围或取值集合不同
- 命名冲突:不同意义的对象具有相同名字 or 相同意义的对象具有不同名字
- 结构冲突:同一对象在不同应用中具有不同层次的抽象;同一实体拥有不同的属性
生成基本 E-R 图:对初步 E-R 图消除冗余;方法包括分析法 + 规范化
冗余数据:可由基本数据导出的数据;系总人数 = \(\sum \text{各系人数}\),系总人数为冗余数据
冗余联系:可由其它联系导出的联系
规范化消除冗余联系:筛除分E-R图中的冗余关系
- 确定分E-R图中的数据依赖:将每对联系表示为实体码间的函数依赖集合F
- 对上述依赖集进行极小化处理获得 \(\text{F}_m\),设 D = F - \(\text{F}_m\)
- 考察 D 中的每个依赖式,筛除其中的冗余联系
注意:冗余信息或许能够提高数据库效率,可以选择保留
三、逻辑结构设计
- E-R 图向关系模式的转化:
- 实体型 \(\Rightarrow\) 关系模式:关系的属性 \(\gets\) 实体的属性;关系的码 \(\gets\) 实体的码
- 联系 \(\Rightarrow\)
关系模式:关系的属性 \(\gets\)
各实体的码 + 联系的属性
- 1: 1联系:每个实体的码都是该关系的候选码
- 1: n联系:该关系的码是n端实体的码(唯一确定性)
- n: m联系:该关系的码是两端实体码的组合(唯一确定性)
- 关系模型的优化:考虑 水平分解 + 垂直分解
- 水平分解:将经常使用的那部分元组分离出来单独作为一个关系
- 垂直分解:将关系模式R中经常在一起使用的属性分解出来形成子模式
四、物理结构设计
数据库物理结构:包含物理设备上的 存储结构 + 存取方法
存取方法:包括 索引 + 聚集 + HASH
索引记录:索引文件中的记录,包括 索引域 + 指针;常用 B+ 树
- 索引域:存储数据文件中若干域的特定值K
注意:索引域应选择经常被查询到的属性、max(min)函数的参数、连接属性等 - 指针:指向索引域值K的记录所在磁盘块的地址
注意:索引也会占据内存,同时具有维护开销,故索引不是越多越好
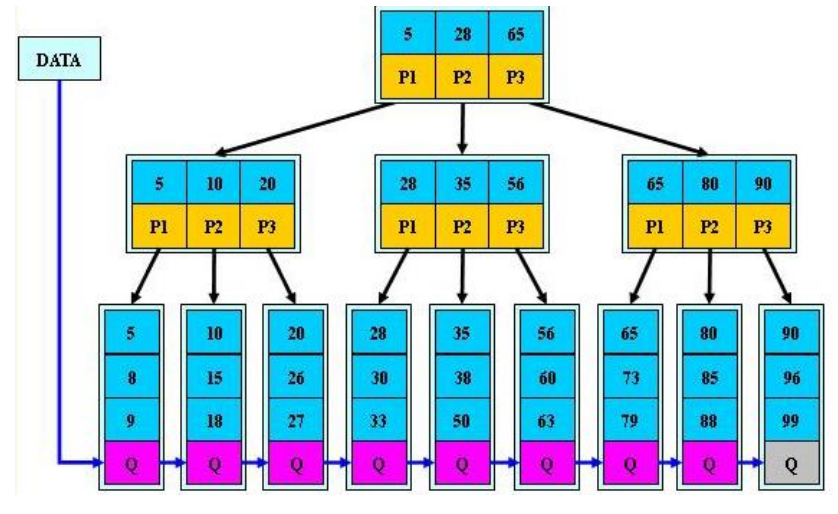
各关键字按递增顺序 从左到右 链接在叶结点上 - 索引域:存储数据文件中若干域的特定值K
聚集:将在若干属性上值相同的记录集中存放在连续的物理块上
- 选择原则:经常进行自然连接操作的关系、某属性值重复率高的模式
注意:建立聚集系统的开销很大,对于更新操作远多于连接操作的关系,不应建立聚集
HASH:利用hash函数将记录关键字转化为地址;记录r(A上值为a)的存储地址 addr = hash(a)
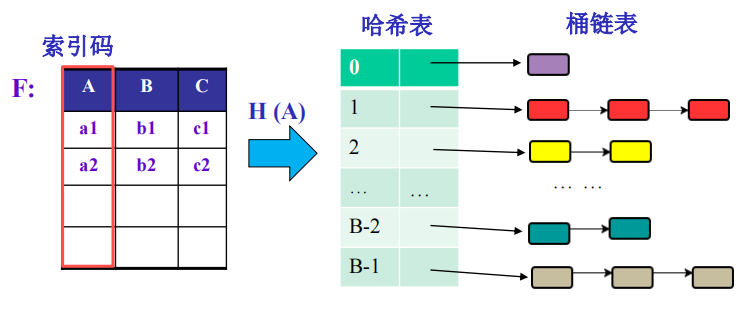
Hash查找