『machine learning-4』linear model
线性模型
一、回归模型
- “回归”:样本倾向于接近以平均值
- 回归函数:\(f(x, \omega) = \sum_{i=0}^{m}
\omega_i \phi_i(x) = \omega^T \phi(x)\),其中 \(\phi\)
表示基函数,x表示样本特征
- 线性函数:\(\phi_i(x)\) = \(x_i\),这种最简单
- 多项式函数:\(\phi_i(x)=x^i\)
- 高斯函数:\(\phi_i(x) = e^{-\frac{(x-\mu_i)^2}{2s^2}}\),其中 \(\mu_i\) 表示样本均值,s表示样本方差
二、梯度下降
损失函数\(J(\omega)\):以最小化训练集预测值f和真实输出y之间的差异为目标,一般情况下: \[ J(\omega) = \frac{1}{2} \sum_{i=1}^N (f(x_i) - y_i)^2 \]
梯度下降求解法:以负梯度方向为搜索方向,越接近目标值,步长越小
设参数初始值为 \(\omega^0\)
更新 \(\omega\) 使得\(J(\omega)\)减小,即对参数向量 \(\omega\) 的第 j 个分量 \(\omega_j\) 有: \[ \begin{align} \omega_j^t &= \omega_j^{t-1} - \alpha \frac{\partial}{\partial \omega_j}J(\omega) \\ 其中 \text{ } \frac{\partial}{\partial \omega_j} J(\omega) &= \sum_{i=1}^{N} [(f(x_i) - y_i) \cdot x_{ij}] \end{align} \]
使 \(J(\omega)\) 取最小值的极值点 \(\omega^*\) 即为线性模型的参数 \(\omega\)
注意:样本量较小时使用求偏导解方程组求解(规避大矩阵);样本量较大时可使用梯度下降法求解
三、线性判别函数
贝叶斯估计的可能问题:
类条件概率密度 \(p(x \text{ | }\omega_i)\) 参数未知
即便参数可以通过样本估计得到,其形式仍难以确定
非参数估计方法需要大量样本
注意:线性判别函数可以根据样本集直接设计分类器,避免了繁杂的统计工作
线性判别函数:一般形式为 \(g(x) = \omega^T x + \omega_0\),其中 x 是样本特征向量
若 \(g(x) \gt 0\),则 \(x \in C_1\)
若 \(g(x) \lt 0\),则 \(x \in C_2\)
若 \(g(x) = 0\),则可将样本 \(x\) 划分为任意一类或拒绝
线性判别函数 \(g(x)\) 即为超平面方程,\(\dfrac{g(x)}{|{|{\omega}}||}\)表示样本点 x 与超平面 \(g(x)\) 的有向距离
注意:可以引入基函数 \(\phi\),利用线性函数的简单性解决复杂问题;但可能导致“维数灾难”
求解线性分类器:分类器的设计 \(\Leftrightarrow\) 求准则函数极值点,求解步骤如下
- 获得样本集\(X = \{x_1, \dots x_N\}\)
- 确定准则函数\(J\):满足 \(J\) 是样本集与 \(\omega\) 的函数,且 \(J\) 的极值对应最佳决策
- 求解准则函数 \(J\) 的极值点\(\omega_0^*\),获得线性判别函数
Fisher 准则:将 d 维空间的样本投影到一维空间(直线上),总可以找到某个方向
使得样本在该方向上的投影分离效果最好,以二分类问题为例:求解两类样本各自的样本均值 \(m_i = \dfrac{1}{N_i} \sum_{y \in C_i} y\),其中 \(i = 1, 2\)
求解样本类内散度 \(S_i^2 = \sum_{y \in C_i} (y - m_i)(y - m_i)^T\),其中 \(i = 1, 2\)
求解 Fisher 准则函数的极大值点,\(J_F(\omega) = \dfrac{(m_i - m_2)^2}{S_1^2 + S_2^2}\)
Lagrange乘子法求解结果:\(\omega^* = S_{\omega}^{-1}(m_1 - m_2)\),其中: \[ S_{\omega} = \sum_{y \in C_1} (y-m_1)(y-m_1)^T + \sum_{y \in C_2}(y-m_2)(y-m_2)^T = S_1^2 + S_2^2 \]
获得线性判别函数 \(y = \omega^* x\),并设置决策阈值用于分类
注意:Fisher准则目标在于尽可能使两类均值之差增大(分子),同时尽可能使各样本内部聚集(分母)
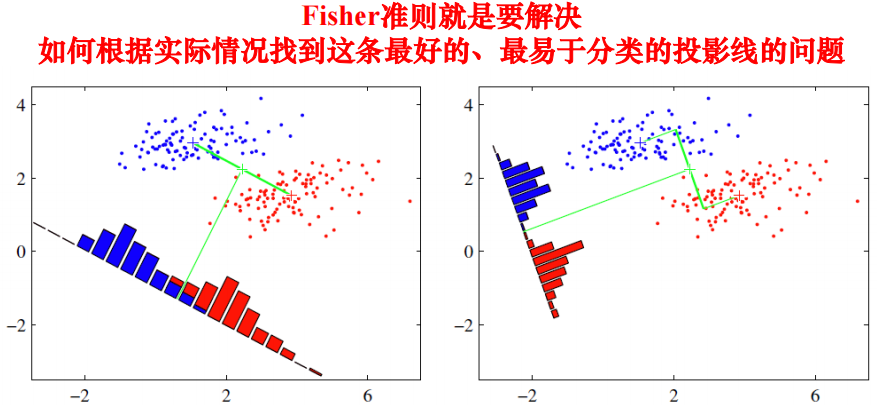
寻找最佳投影直线 线性可分性:设数据集 D = \(\{(x_1, y_1), \dots (x_N, y_N)\}\),\(x_i \in \mathbb{R}^d\),\(y_i \in \{+1, -1\}\)
若存在某个超平面S: \(\omega x + b = 0\),使得 \(y_i (\omega x_i + b) \lt 0\) 对任意的 \(x_i\) 恒成立,说明该数据集是线性可分的感知机准则:设置损失函数,\(J(\omega, \omega_0) = -\sum_{x_i \in M} y_i(\omega x_i + \omega_0)\),其中\(M\)表示误分类样本的集合
- 任选一个初始超平面 \(\omega, \omega_0\),使用随机梯度下降法求解 \(\min (J(\omega, \omega_0))\)
- 若存在样本点\((x_i, y_i)\),使得
\(y_i(\omega x_i + \omega_0) \le
0\)(被误识别)
则更新 \(\omega \gets \omega + \eta y_i x_i\),\(\omega_0 \gets \omega_0 + \eta y_i\)(\(0 \lt \eta \le 1\) 表示学习率)
注意:迭代每一步,表示使超平面不断靠近被错分类的点,最终被正确分类 - 反复迭代直至没有被误识别的样本点(\(J(\omega, \omega_0)\) = 0)
注意:超平面初始值不同,最终解出的超平面也可能不同