『machine learning-1』overview
概述
一、与机器学习相关的学科
- 人工智能
- 智能信息处理
- 模式识别
- 数据挖掘
- 计算机视觉
- 自然语言处理
二、机器学习算法
机器学习的主要问题:
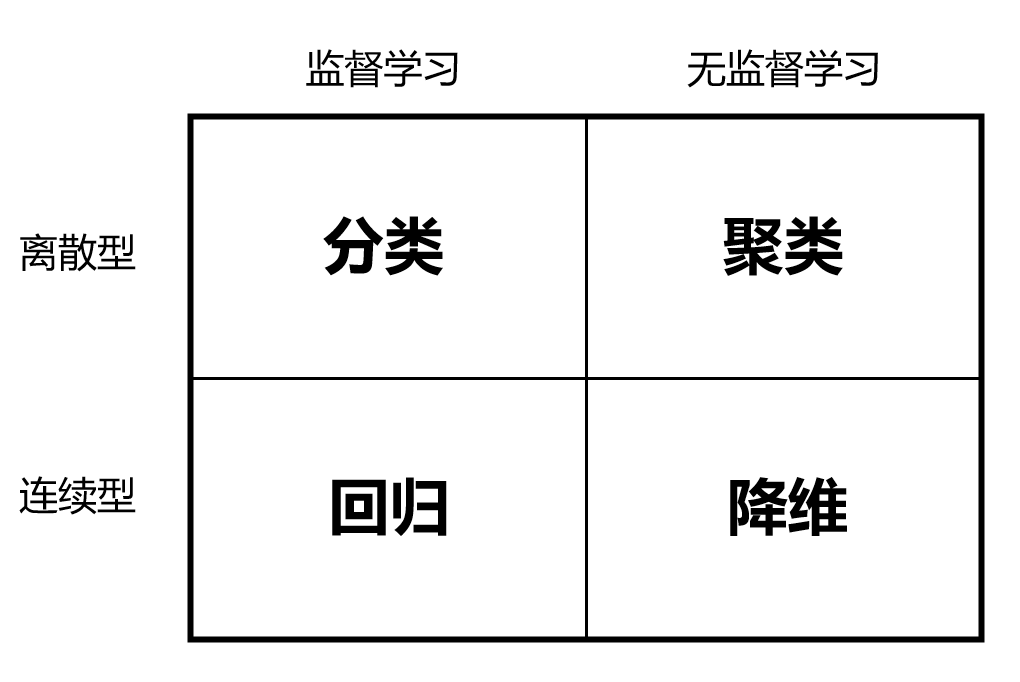
机器学习典型算法
监督学习:利用已标记的数据训练模型;\(\{\text{x}_i \in \mathbb{R}^d, y_i \in \mathbb{R} \}_{i=1}^N\)
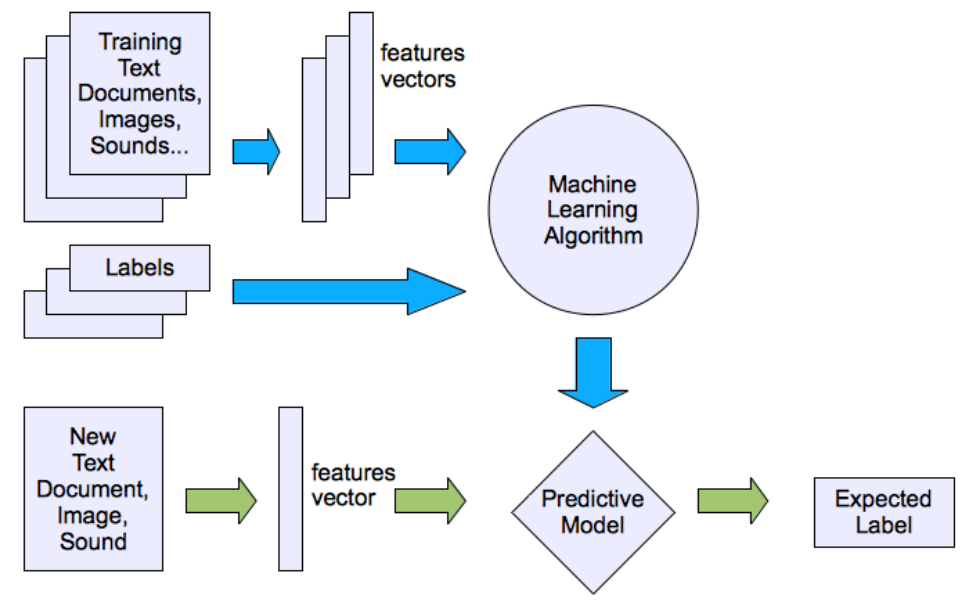
监督学习
非监督学习:利用未标记的数据训练模型,需要模型自行发掘数据中的特征;\(\{\text{x}_i \in \mathbb{R}^d\}_{i=1}^N\)
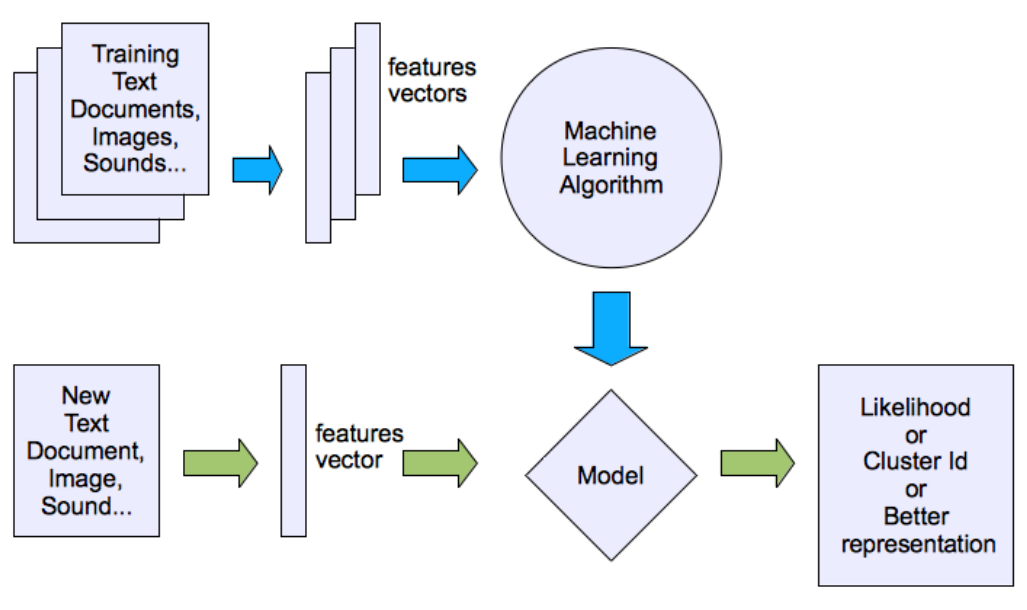
非监督学习
半监督学习:训练数据集中同时混有已标记和未标记的数据
注意:“监督学习”与“非监督学习”的差异在于训练集中是否含有目标值
三、训练与测试
No Free Lunch :没有一种单一的机器学习算法能够在所有问题上表现得最好
影响机器学习结果的因素:
- 训练的类型
- 初始背景知识的形式与范围
- 训练反馈的类型
- 机器学习算法
机器学习的目标:
- 监督学习:尽可能缩小测试集上的预测误差,其中测试集误差 \(\text{Error}_{out} = \dfrac{1}{N} \sum_{i=1}^N (y_i \ne g(x_i))\)
- 非监督学习:缺少预先定义的标准答案;一般结合实际领域与需求对测试结果进行解释与判断
“偏差”与“方差”:
- 偏差:用所有可能的训练集训练出的所有模型的输出平均值与真实模型输出值之间的差异
- 方差:用不同训练集训练出的模型输出值之间的差异
“过拟合”与“欠拟合”:
过拟合:模型过于复杂,学习了训练集中大量无关特征(噪声)
特点:低偏差 + 高方差(抗噪性弱)、低训练集误差 + 高测试集误差欠拟合:模型过于简单,无法充分学习数据中相关特征
特点:高偏差(算法拟合能力差) + 低方差、高训练集误差 + 高测试集误差注意:“偏差”与“方差”是矛盾的
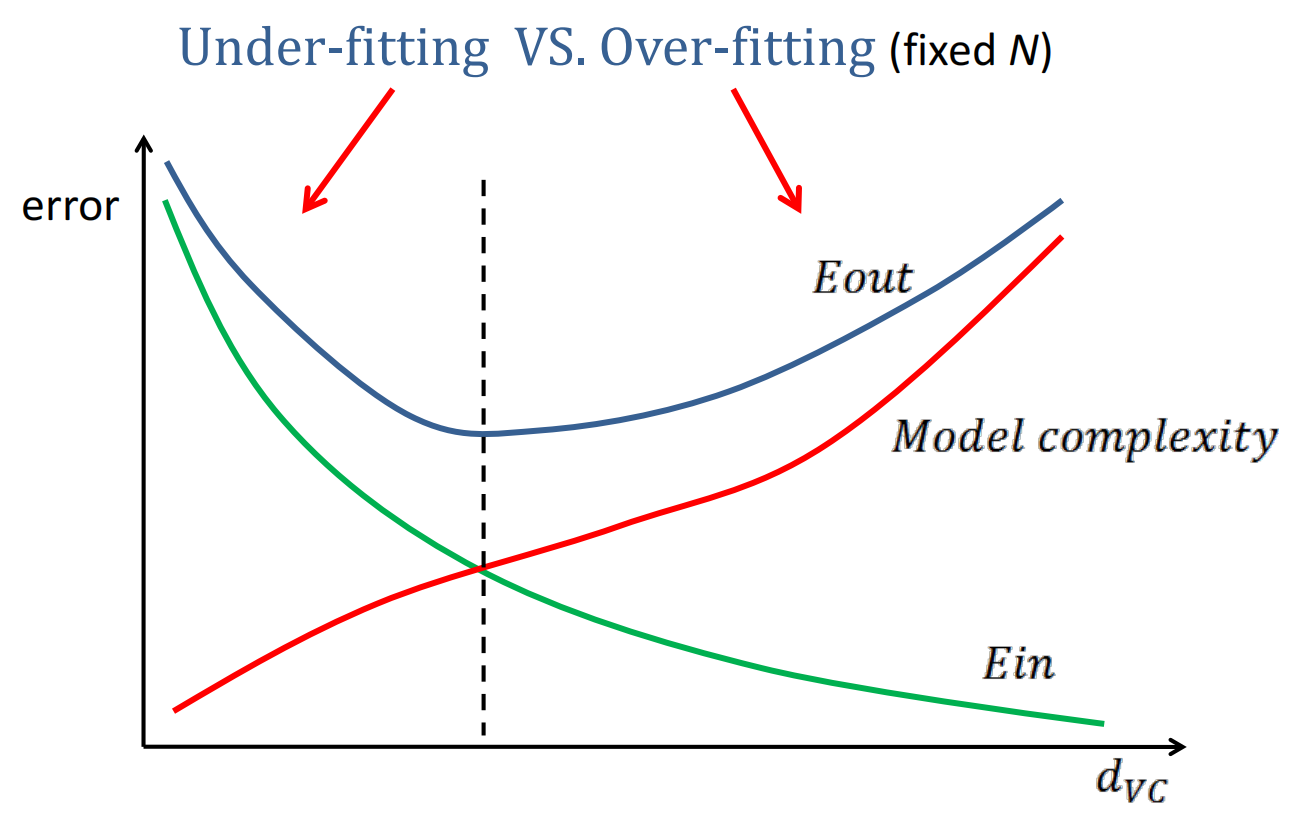
训练集误差(Ein)、测试集误差(Eout)与模型复杂度(dvc)之间的关系
泛化误差:\(\text{GE} = \text{noise}^2 + \text{bias}^2 + \text{variance}\)
其中 noise 是训练集的噪声,不可避免;bias 由模型错误的假设造成;variance 由各训练集间的偏差造成
『machine learning-1』overview
http://larry0454.github.io/2023/07/20/machine_learning/overview/